

The genetic code is a set of rules by which the information encoded in genetic material (DNA or RNA sequences) is translated into proteins by living cells. Specifically, the genetic code defines how sequences of nucleotide triplets, called codons, specify which amino acids are added to a growing polypeptide chain during the process of translation.
1. Structure of the Genetic Code
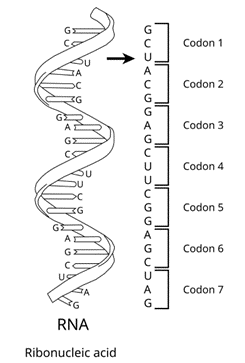
Codons: The genetic code consists of codons, which are sequences of three nucleotides. Each codon corresponds to a specific amino acid or a stop signal during protein synthesis.
Nucleotides: The four nucleotides in RNA are adenine (A), uracil (U), cytosine (C), and guanine (G). In DNA, thymine (T) replaces uracil.
64 Codons: With four possible nucleotides at each of the three positions, there are 4^3 = 64 possible codons.
2. Characteristics of the Genetic Code:
Universality: The genetic code is nearly universal, meaning it is used by almost all organisms, from bacteria to humans, with very few exceptions (e.g., some mitochondrial genomes and some protozoa).
Degeneracy (Redundancy): Most amino acids are encoded by more than one codon. This redundancy helps protect against mutations, as changes in the third nucleotide of a codon often do not alter the amino acid.
Non-overlapping: Codons are read one at a time in a continuous sequence, without overlapping or skipping nucleotides.
Unambiguous: Each codon specifies only one amino acid or a stop signal.
Start and Stop Signals: There are specific codons that signal the start and end of protein synthesis.
Start Codon: AUG, which codes for methionine, also serves as the start codon for translation.
Stop Codons: UAA, UAG, and UGA do not code for any amino acids but instead signal the termination of translation.
3. Reading Frame:
Reading Frame: The sequence of codons is read in a specific frame, starting from a start codon to a stop codon. A shift in the reading frame, caused by insertions or deletions, can lead to a completely different translation, often resulting in a nonfunctional protein.
Open Reading Frame (ORF): A sequence of DNA or RNA that could be translated to give a polypeptide. An ORF typically begins with a start codon and ends with a stop codon.
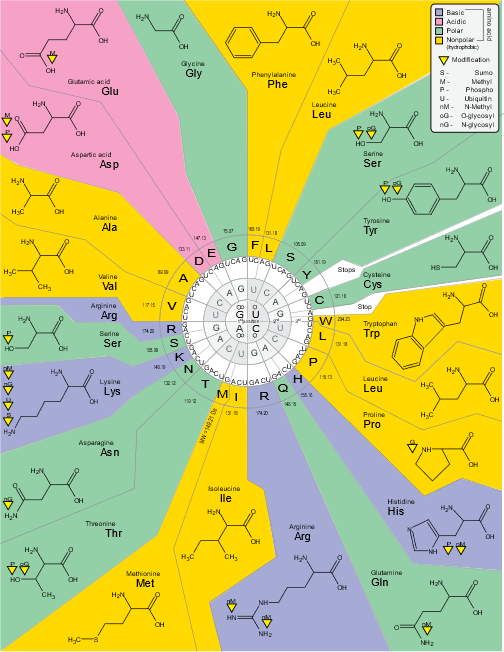
4. Amino Acids and Their Codons:
Methionine (Met): AUG
Phenylalanine (Phe): UUU, UUC
Leucine (Leu): UUA, UUG, CUU, CUC, CUA, CUG
Isoleucine (Ile): AUU, AUC, AUA
Valine (Val): GUU, GUC, GUA, GUG
Serine (Ser): UCU, UCC, UCA, UCG, AGU, AGC
Proline (Pro): CCU, CCC, CCA, CCG
Threonine (Thr): ACU, ACC, ACA, ACG
Alanine (Ala): GCU, GCC, GCA, GCG
Tyrosine (Tyr): UAU, UAC
Histidine (His): CAU, CAC
Glutamine (Gln): CAA, CAG
Asparagine (Asn): AAU, AAC
Lysine (Lys): AAA, AAG
Aspartic acid (Asp): GAU, GAC
Glutamic acid (Glu): GAA, GAG
Cysteine (Cys): UGU, UGC
Tryptophan (Trp): UGG
Arginine (Arg): CGU, CGC, CGA, CGG, AGA, AGG
Glycine (Gly): GGU, GGC, GGA, GGG
5. Special Codons:
Start Codon (AUG): Initiates translation and codes for methionine.
Stop Codons (UAA, UAG, UGA): Signal the end of translation, do not code for any amino acid.
6. Exceptions to the Genetic Code:
Mitochondrial DNA: Mitochondria have their own DNA and sometimes use slightly different codons. For example, in human mitochondria, AUA codes for methionine instead of isoleucine.
Protozoa and Some Fungi: Some protozoa and fungi have slight variations in their genetic code, such as using UGA to encode tryptophan instead of serving as a stop codon.
7. Evolution and Origin of the Genetic Code:
Evolutionary Conservation: The universality of the genetic code suggests that it arose early in the evolution of life and has been conserved due to its efficiency and robustness.
Adaptive Significance: The redundancy and degeneracy of the genetic code may provide a buffer against mutations, reducing the impact of errors during DNA replication and protein synthesis.
Practical Applications of the Genetic Code
1. Genetic Engineering: Understanding the genetic code allows scientists to manipulate genetic material, creating genetically modified organisms (GMOs) with desired traits.
2. Synthetic Biology: Scientists can design synthetic genes and proteins by exploiting the genetic code, leading to the development of new biomolecules and organisms.
3. Gene Therapy: By correcting faulty genes, researchers can treat genetic disorders by ensuring the proper proteins are synthesized in patients’ cells.
4. Molecular Medicine: Knowledge of the genetic code aids in the development of personalized medicine, where treatments can be tailored based on an individual’s genetic makeup.
5. Biotechnology: The genetic code is fundamental to various biotechnological applications, including the production of recombinant proteins, enzymes, and pharmaceuticals.
Understanding the genetic code is crucial for numerous fields, including genetics, molecular biology, biotechnology, and medicine. It serves as the foundation for decoding the information stored in DNA and translating it into functional proteins essential for life.
Visit to: Pharmacareerinsider.com